John Goerzen: Consider Security First
I write this in the context of my decision to ditch Raspberry Pi OS and move everything I possibly can, including my Raspberry Pi devices, to Debian. I will write about that later.
But for now, I wanted to comment on something I think is often overlooked and misunderstood by people considering distributions or operating systems: the huge importance of getting security updates in an automated and easy way.
Background
Let s assume that these statements are true, which I think are well-supported by available evidence:
Background
Let s assume that these statements are true, which I think are well-supported by available evidence:
-
Every computer system (OS plus applications) that can do useful modern work has security vulnerabilities, some of which are unknown at any given point in time;
-
During the lifetime of that computer system, some of these vulnerabilities will be discovered. For a (hopefully large) subset of those vulnerabilities, timely patches will become available.
Now then, it follows that applying those timely patches is a critical part of having a system that it as secure as possible. Of course, you have to do other things as well good passwords, secure practices, etc but, fundamentally, if your system lacks patches for known vulnerabilities, you ve already lost at the security ballgame.
How to stay patched
There is something of a continuum of how you might patch your system. It runs roughly like this, from best to worst:
-
All components are kept up-to-date automatically, with no intervention from the user/operator
-
The operator is automatically alerted to necessary patches, and they can be easily installed with minimal intervention
-
The operator is automatically alerted to necessary patches, but they require significant effort to apply
-
The operator has no way to detect vulnerabilities or necessary patches
It should be obvious that the first situation is ideal. Every other situation relies on the timeliness of human action to keep up-to-date with security patches. This is a fallible situation; humans are busy, take trips, dismiss alerts, miss alerts, etc. That said, it is rare to find any system living truly all the way in that scenario, as you ll see.
What is your system ?
A critical point here is: what is your system ? It includes:
- Your kernel
- Your base operating system
- Your applications
- All the libraries needed to run all of the above
Some OSs, such as Debian, make little or no distinction between the base OS and the applications. Others, such as many BSDs, have a distinction there. And in some cases, people will compile or install applications outside of any OS mechanism. (It must be stressed that by doing so, you are taking the responsibility of patching them on your own shoulders.)
How do common systems stack up?
-
Debian, with its support for unattended-upgrades, needrestart, debian-security-support, and such, is largely category 1. It can automatically apply security patches, in most cases can restart the necessary services for the patch to take effect, and will alert you when some processes or the system must be manually restarted for a patch to take effect (for instance, a kernel update). Those cases requiring manual intervention are category 2. The debian-security-support package will even warn you of gaps in the system. You can also use debsecan to scan for known vulnerabilities on a given installation.
-
FreeBSD has no way to automatically install security patches for things in the packages collection. As with many rolling-release systems, you can t automate the installation of these security patches with FreeBSD because it is not safe to blindly update packages. It s not safe to blindly update packages because they may bring along more than just security patches: they may represent major upgrades that introduce incompatibilities, etc. Unlike Debian s practice of backporting fixes and thus producing narrowly-tailored patches, forcing upgrades to newer versions precludes a minimal intervention install. Therefore, rolling release systems are category 3.
-
Things such as Snap, Flatpak, AppImage, Docker containers, Electron apps, and third-party binaries often contain embedded libraries and such for which you have no easy visibility into their status. For instance, if there was a bug in libpng, would you know how many of your containers had a vulnerability? These systems are category 4 you don t even know if you re vulnerable. It s for this reason that my Debian-based Docker containers apply security patches before starting processes, and also run unattended-upgrades and friends.
The pernicious library problem
As mentioned in my last category above, hidden vulnerabilities can be a big problem. I ve been writing about this for years. Back in 2017, I wrote an article focused on Docker containers, but which applies to the other systems like Snap and so forth. I cited a study back then that Over 80% of the :latest versions of official images contained at least one high severity vulnerability. The situation is no better now. In December 2023, it was reported that, two years after the critical Log4Shell vulnerability, 25% of apps were still vulnerable to it. Also, only 21% of developers ever update third-party libraries after introducing them into their projects.
Clearly, you can t rely on these images with embedded libraries to be secure. And since they are black box, they are difficult to audit.
Debian s policy of always splitting libraries out from packages is hugely beneficial; it allows finegrained analysis of not just vulnerabilities, but also the dependency graph. If there s a vulnerability in libpng, you have one place to patch it and you also know exactly what components of your system use it.
If you use snaps, or AppImages, you can t know if they contain a deeply embedded vulnerability, nor could you patch it yourself if you even knew. You are at the mercy of upstream detecting and remedying the problem a dicey situation at best.
Who makes the patches?
Fundamentally, humans produce security patches. Often, but not always, patches originate with the authors of a program and then are integrated into distribution packages. It should be noted that every security team has finite resources; there will always be some CVEs that aren t patched in a given system for various reasons; perhaps they are not exploitable, or are too low-impact, or have better mitigations than patches.
Debian has an excellent security team; they manage the process of integrating patches into Debian, produce Debian Security Advisories, maintain the Debian Security Tracker (which maintains cross-references with the CVE database), etc.
Some distributions don t have this infrastructure. For instance, I was unable to find this kind of tracker for Devuan or Raspberry Pi OS. In contrast, Ubuntu and Arch Linux both seem to have active security teams with trackers and advisories.
Implications for Raspberry Pi OS and others
As I mentioned above, I m transitioning my Pi devices off Raspberry Pi OS (Raspbian). Security is one reason. Although Raspbian is a fork of Debian, and you can install packages like unattended-upgrades on it, they don t work right because they use the Debian infrastructure, and Raspbian hasn t modified them to use their own infrastructure. I don t see any Raspberry Pi OS security advisories, trackers, etc. In short, they lack the infrastructure to support those Debian tools anyhow.
Not only that, but Raspbian lags behind Debian in both new releases and new security patches, sometimes by days or weeks.
Live Migrating from Raspberry Pi OS bullseye to Debian bookworm contains instructions for migrating Raspberry Pis to Debian.
- All components are kept up-to-date automatically, with no intervention from the user/operator
- The operator is automatically alerted to necessary patches, and they can be easily installed with minimal intervention
- The operator is automatically alerted to necessary patches, but they require significant effort to apply
- The operator has no way to detect vulnerabilities or necessary patches
What is your system ?
A critical point here is: what is your system ? It includes:
- Your kernel
- Your base operating system
- Your applications
- All the libraries needed to run all of the above
Some OSs, such as Debian, make little or no distinction between the base OS and the applications. Others, such as many BSDs, have a distinction there. And in some cases, people will compile or install applications outside of any OS mechanism. (It must be stressed that by doing so, you are taking the responsibility of patching them on your own shoulders.)
How do common systems stack up?
-
Debian, with its support for unattended-upgrades, needrestart, debian-security-support, and such, is largely category 1. It can automatically apply security patches, in most cases can restart the necessary services for the patch to take effect, and will alert you when some processes or the system must be manually restarted for a patch to take effect (for instance, a kernel update). Those cases requiring manual intervention are category 2. The debian-security-support package will even warn you of gaps in the system. You can also use debsecan to scan for known vulnerabilities on a given installation.
-
FreeBSD has no way to automatically install security patches for things in the packages collection. As with many rolling-release systems, you can t automate the installation of these security patches with FreeBSD because it is not safe to blindly update packages. It s not safe to blindly update packages because they may bring along more than just security patches: they may represent major upgrades that introduce incompatibilities, etc. Unlike Debian s practice of backporting fixes and thus producing narrowly-tailored patches, forcing upgrades to newer versions precludes a minimal intervention install. Therefore, rolling release systems are category 3.
-
Things such as Snap, Flatpak, AppImage, Docker containers, Electron apps, and third-party binaries often contain embedded libraries and such for which you have no easy visibility into their status. For instance, if there was a bug in libpng, would you know how many of your containers had a vulnerability? These systems are category 4 you don t even know if you re vulnerable. It s for this reason that my Debian-based Docker containers apply security patches before starting processes, and also run unattended-upgrades and friends.
The pernicious library problem
As mentioned in my last category above, hidden vulnerabilities can be a big problem. I ve been writing about this for years. Back in 2017, I wrote an article focused on Docker containers, but which applies to the other systems like Snap and so forth. I cited a study back then that Over 80% of the :latest versions of official images contained at least one high severity vulnerability. The situation is no better now. In December 2023, it was reported that, two years after the critical Log4Shell vulnerability, 25% of apps were still vulnerable to it. Also, only 21% of developers ever update third-party libraries after introducing them into their projects.
Clearly, you can t rely on these images with embedded libraries to be secure. And since they are black box, they are difficult to audit.
Debian s policy of always splitting libraries out from packages is hugely beneficial; it allows finegrained analysis of not just vulnerabilities, but also the dependency graph. If there s a vulnerability in libpng, you have one place to patch it and you also know exactly what components of your system use it.
If you use snaps, or AppImages, you can t know if they contain a deeply embedded vulnerability, nor could you patch it yourself if you even knew. You are at the mercy of upstream detecting and remedying the problem a dicey situation at best.
Who makes the patches?
Fundamentally, humans produce security patches. Often, but not always, patches originate with the authors of a program and then are integrated into distribution packages. It should be noted that every security team has finite resources; there will always be some CVEs that aren t patched in a given system for various reasons; perhaps they are not exploitable, or are too low-impact, or have better mitigations than patches.
Debian has an excellent security team; they manage the process of integrating patches into Debian, produce Debian Security Advisories, maintain the Debian Security Tracker (which maintains cross-references with the CVE database), etc.
Some distributions don t have this infrastructure. For instance, I was unable to find this kind of tracker for Devuan or Raspberry Pi OS. In contrast, Ubuntu and Arch Linux both seem to have active security teams with trackers and advisories.
Implications for Raspberry Pi OS and others
As I mentioned above, I m transitioning my Pi devices off Raspberry Pi OS (Raspbian). Security is one reason. Although Raspbian is a fork of Debian, and you can install packages like unattended-upgrades on it, they don t work right because they use the Debian infrastructure, and Raspbian hasn t modified them to use their own infrastructure. I don t see any Raspberry Pi OS security advisories, trackers, etc. In short, they lack the infrastructure to support those Debian tools anyhow.
Not only that, but Raspbian lags behind Debian in both new releases and new security patches, sometimes by days or weeks.
Live Migrating from Raspberry Pi OS bullseye to Debian bookworm contains instructions for migrating Raspberry Pis to Debian.
- Debian, with its support for unattended-upgrades, needrestart, debian-security-support, and such, is largely category 1. It can automatically apply security patches, in most cases can restart the necessary services for the patch to take effect, and will alert you when some processes or the system must be manually restarted for a patch to take effect (for instance, a kernel update). Those cases requiring manual intervention are category 2. The debian-security-support package will even warn you of gaps in the system. You can also use debsecan to scan for known vulnerabilities on a given installation.
- FreeBSD has no way to automatically install security patches for things in the packages collection. As with many rolling-release systems, you can t automate the installation of these security patches with FreeBSD because it is not safe to blindly update packages. It s not safe to blindly update packages because they may bring along more than just security patches: they may represent major upgrades that introduce incompatibilities, etc. Unlike Debian s practice of backporting fixes and thus producing narrowly-tailored patches, forcing upgrades to newer versions precludes a minimal intervention install. Therefore, rolling release systems are category 3.
- Things such as Snap, Flatpak, AppImage, Docker containers, Electron apps, and third-party binaries often contain embedded libraries and such for which you have no easy visibility into their status. For instance, if there was a bug in libpng, would you know how many of your containers had a vulnerability? These systems are category 4 you don t even know if you re vulnerable. It s for this reason that my Debian-based Docker containers apply security patches before starting processes, and also run unattended-upgrades and friends.
 Figure 1: Content-Security-Policy browser communication
This is revolutionary, because it allows servers to receive feedback
in real time on errors that may be appearing in the browser s console.
Figure 1: Content-Security-Policy browser communication
This is revolutionary, because it allows servers to receive feedback
in real time on errors that may be appearing in the browser s console.
 This is a post I wrote in June 2022, but did not publish back then.
After first publishing it in December 2023, a perfectionist insecure
part of me unpublished it again. After receiving positive feedback, i
slightly amended and republish it now.
In this post, I talk about unpaid work in F/LOSS, taking on the example
of hackathons, and why, in my opinion, the expectation of volunteer work
is hurting diversity.
Disclaimer: I don t have all the answers, only some ideas and questions.
This is a post I wrote in June 2022, but did not publish back then.
After first publishing it in December 2023, a perfectionist insecure
part of me unpublished it again. After receiving positive feedback, i
slightly amended and republish it now.
In this post, I talk about unpaid work in F/LOSS, taking on the example
of hackathons, and why, in my opinion, the expectation of volunteer work
is hurting diversity.
Disclaimer: I don t have all the answers, only some ideas and questions.










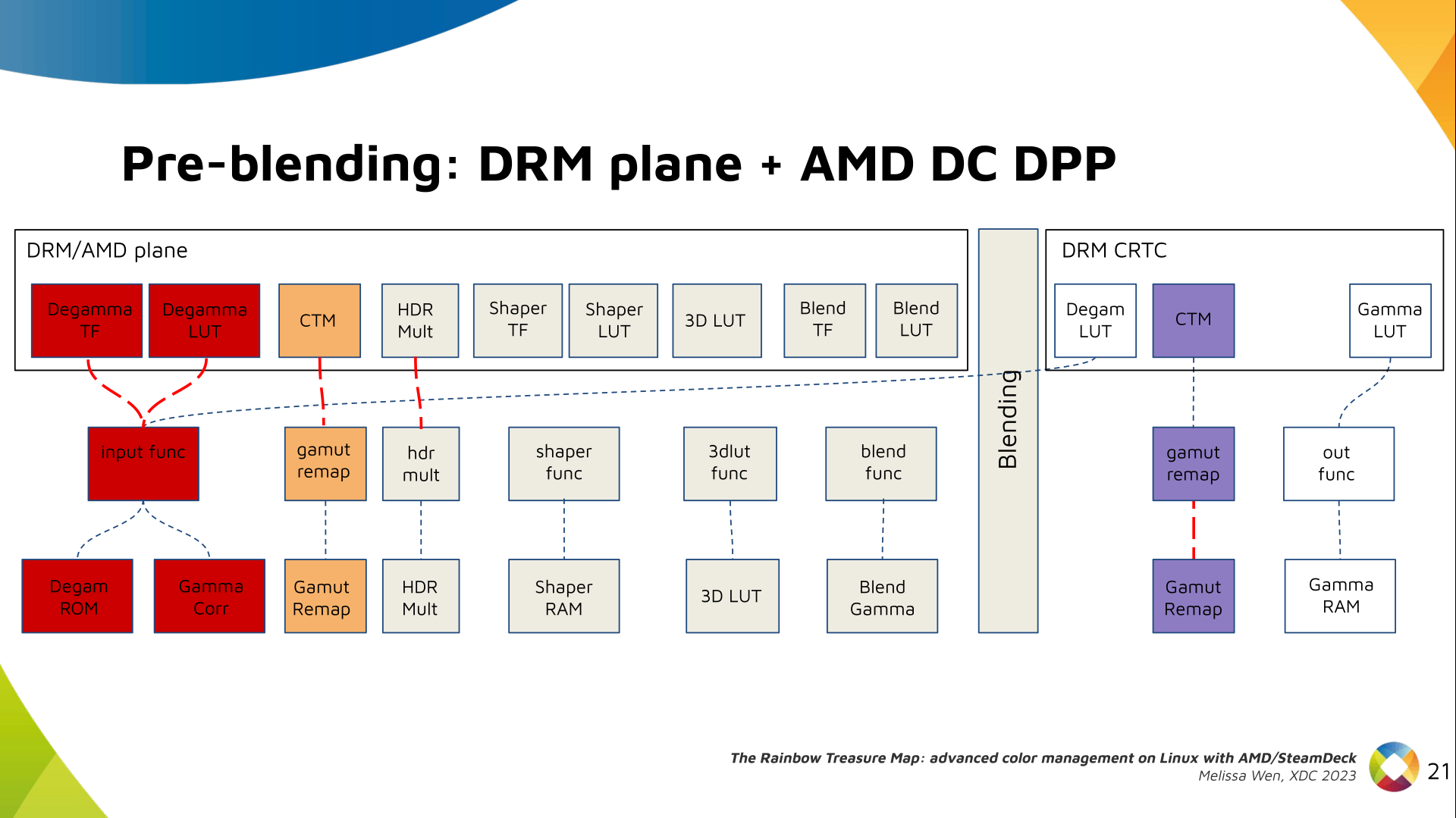

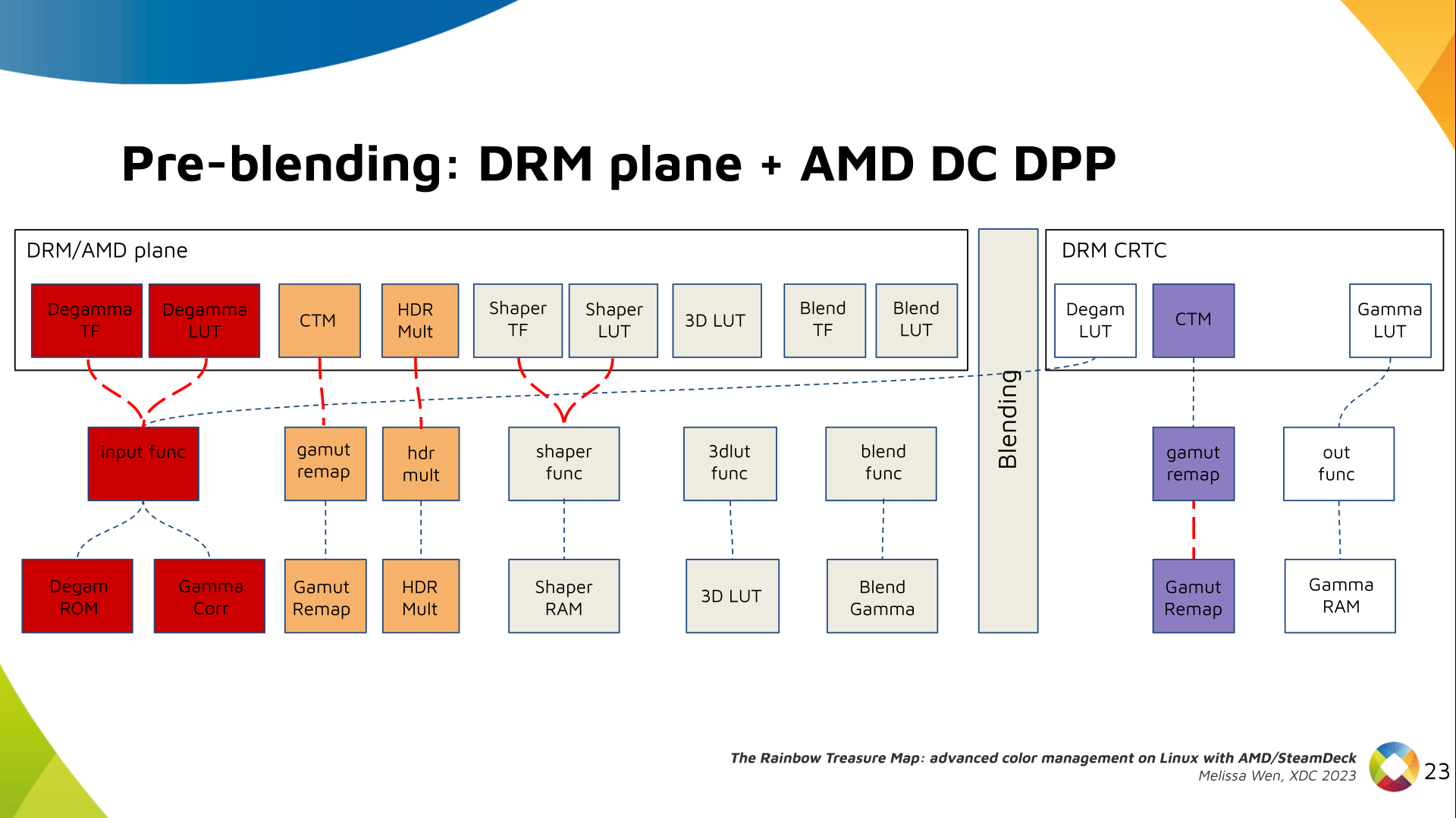

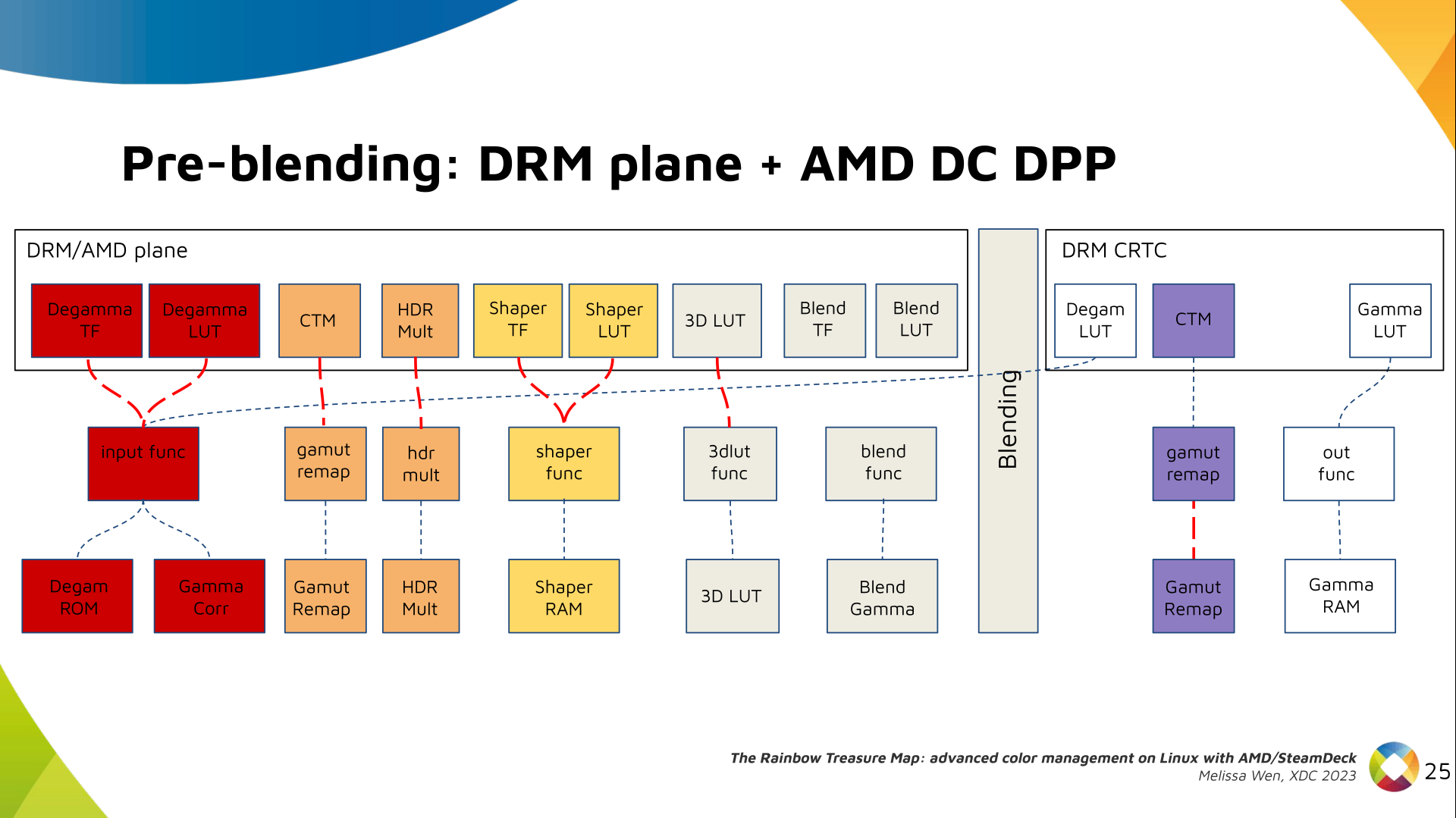

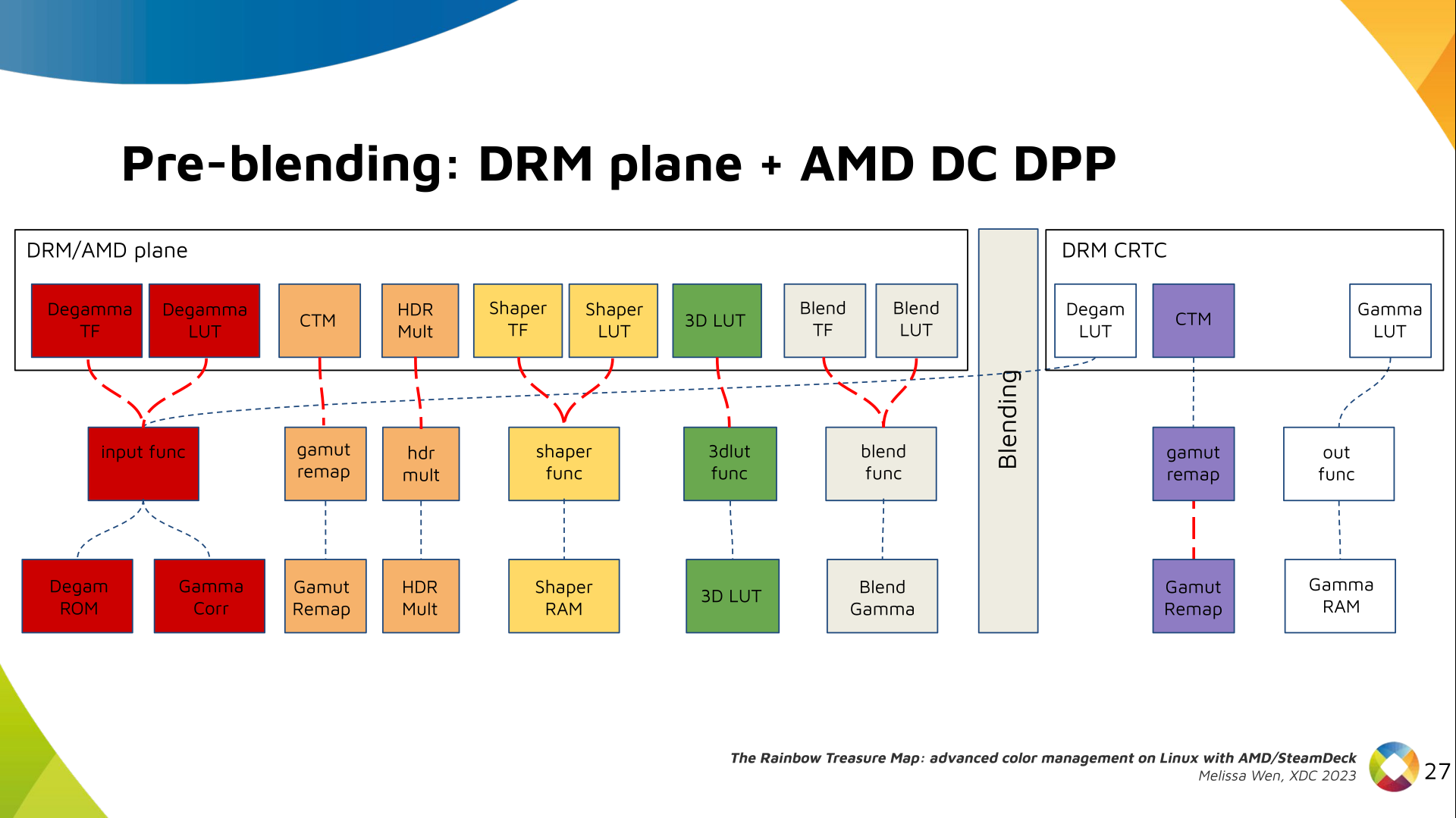













 This week I stumbled across a footgun in the
This week I stumbled across a footgun in the 


{kind=link}